Database indexing internals - B-tree
by Davor Lozic, CTO
Database indexing series:
-
Database indexing - B-tree part 1 - overview
Introduction
Data has become an invaluable asset for organisations worldwide. With the increasing amount of data being generated, there is a need for efficient methods to store, retrieve, and manage vast quantities of information. As databases continue to grow in size, the task of querying data in real-time becomes more challenging. Imagine searching for a single record in a database that contains billions of rows. Without an efficient system, this query could take a significant amount of time (from seconds to hours!). This is where indexing, specifically techniques like B-tree indexing, plays a vital role. To explain B-tree you need to understand simpler concepts like Binary trees (BT) and Binary search trees (BST) so hang tight and enjoy the ride!
Before we start, let’s quickly introduce list of technologies used in the example:
- Python 3 with Faker to generate the data
- Postgres 16 database management system
- Low-resource server on Amazon (few GB of swap memory)
Example
We’ve generated 30M records in Postgres for a simple users table with Python and Faker:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL
);
Let's test the speed of a simple query and ask the database engine to explain its execution plan to us:
-- counting without index - 13s 35ms
SELECT COUNT(*) FROM users WHERE first_name = 'Julie';
-- postgres says it's gonna perform a full-table scan
-- newer versions (> 9.6) will say parallel full-table scan
EXPLAIN SELECT * FROM users WHERE first_name = 'Julie';Now, we will add something called index to a first_name attribute in users relation, ask the engine for its execution plan, and test the query speed:
-- creating index on first_name - 1m 11s
CREATE INDEX idx_users_fn ON users USING btree(first_name);
-- counting with index - 366ms
SELECT COUNT(*) FROM users WHERE first_name = 'Julie';
-- index scan on idx_users_fn -> in other words, using index
EXPLAIN SELECT * FROM users WHERE first_name = 'Julie';What just happened? How did a single line of SQL code, change the execution speed of the same query by a factor of 35?
What is indexing?
At its core, indexing is a database optimization technique that improves data retrieval speeds. Similar to the index section at the end of a book, a database index provides a roadmap to the storage locations of specific data based on one or more columns.
When a database table lacks indexes, retrieving information requires scanning every single record in the table until the desired data is found. This method, known as a full table scan, can be time-consuming and resource-intensive, especially for large databases. An index provides a shortcut, allowing the DBMS to quickly determine where the desired data is located, significantly reducing the number of records it needs to examine.
To create an index, the DBMS processes a specific column or set of columns in the table and constructs a separate data structure, such as a B-tree, that maps the values in these columns to the physical locations of the corresponding rows. Once created, this index enables rapid search and retrieval operations. This technique, of course, doesn’t come without overhead! We’ll talk about limitations and disadvantages later, first let’s discuss what are Trees and B-trees.
What are Trees? What are B-trees?
A tree in computer science is a special type of a graph, collection of nodes connected by edges, with each node containing a value. Unlike arrays or linked lists, which are linear, trees are hierarchical (see Figure 1). Some essential terminology associated with trees:
- Node: Each individual element in the tree, root node strangely being the topmost node [yes, CS terminology can sometimes be funny: killing a parent (process), Ruby programming language has a spermy operator (~>), forking a child, taking a (database) dump].
- Leaf: A node with no children.
- Edge: The link between nodes.
- Parent and Child: Nodes directly connected by an edge, where the parent is one level above the child.
- Depth: The level or tier of a node, with the root being at depth 0.
- Order: Tree’s order determines maximum number of children any node can have.
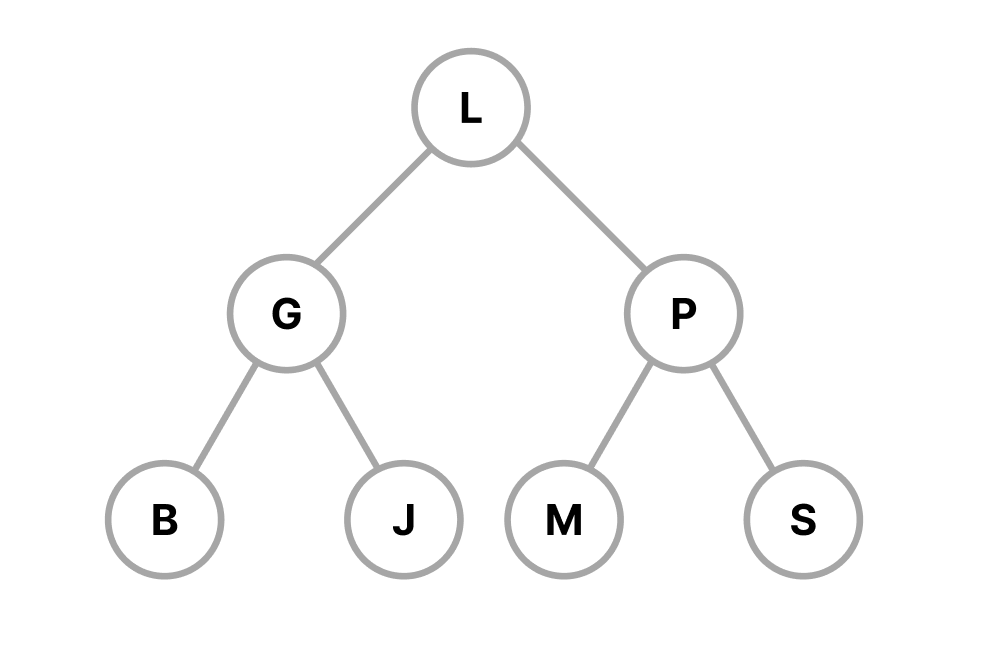
Figure 1: example of a binary (search) tree
Tree structure provide different traversal methods, such as in-order, pre-order, and post-order, which determine the sequence in which nodes are accessed. While there are various types of trees (binary trees, AVL trees, red-black trees, etc.), for the purpose of database indexing, we will focus on B-trees, which have unique balancing properties.
Binary search tree (BST) is a special type of binary tree where nodes are sorted, meaning that the left subtree contains values that are less than the node’s value.
B-trees are a type of tree structure that generalises binary search trees. What sets them apart is their ability to store multiple keys per node, which allows for wider and shorter trees (see Figure 2). This is particularly advantageous when working with storage systems such as hard drives as it minimises the number of disk reads.
Here is a quick overview:
| Feature | Binary tree | B-tree |
|---|---|---|
| Node children | Each node has at most 2 children (left and right). | Nodes can have multiple children, determined by the tree's order. |
| Balancing | Not inherently balanced. | Always balanced by design. Adjusts nodes upon insertion and deletion to maintain balance. |
| Multiple keys | Each node contains a single key. | Nodes can contain multiple keys, especially in larger-order B-trees. |
| Depth | Can become very deep if not balanced, leading to inefficiencies. | Tend to be broader and shallower due to multiple keys and children, optimizing access times. |
| Search efficiency | Efficient degraded in unbalanced scenarios. | Consistently efficient due to its balanced nature, irrespective of data distribution. |
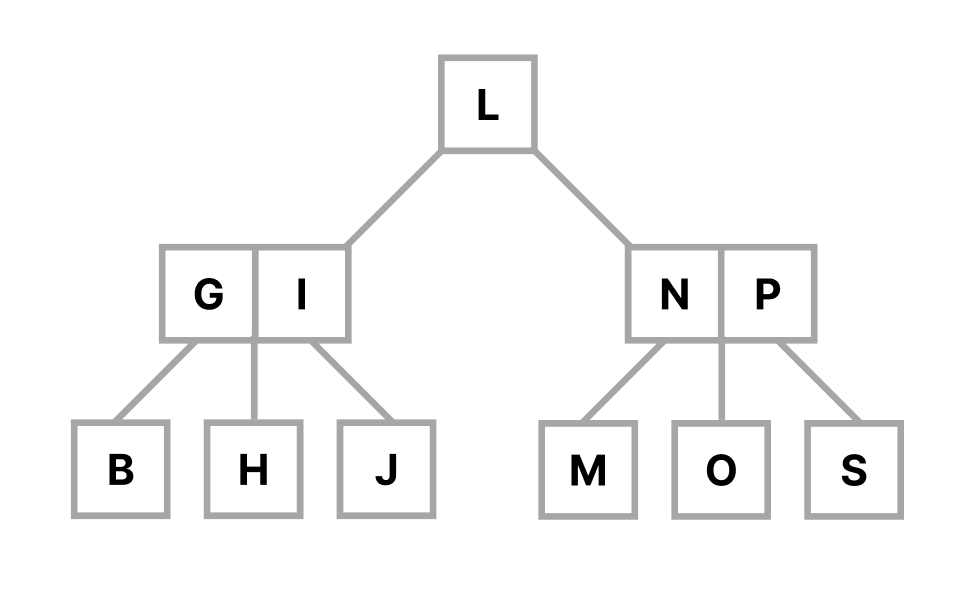
Figure 2: example of a B-tree, generalised version of a binary tree
B-trees have evolved to be integral in the world of databases and file systems due to their adaptability and efficiency in managing large amounts of data. The structure ensures that even with huge volumes of data, only a small number of node accesses are required to find a particular key, making data retrieval exceptionally fast.
OK, I get it, but I still don’t understand why is it so FAST?
Consider a simplified example of a binary search tree (BST), where each letter represents a pointer to the database where the actual data is stored. In this example, we are searching for the letter J, similar to using a database query like WHERE last_name LIKE 'J%'. Instead of traversing and checking every row (full-table scan), you start from the root node and ask "Does J come before or after L?" If it comes before, you continue to the left; if it comes after, you continue to the right. By doing this, after just one hop, we have ignored 50% of the data on average (see Figure 3). You repeat the same process with G, ignoring another 50%, and so on. Now imagine doing this for 10-100 hops instead of scanning the entire table with millions of rows.
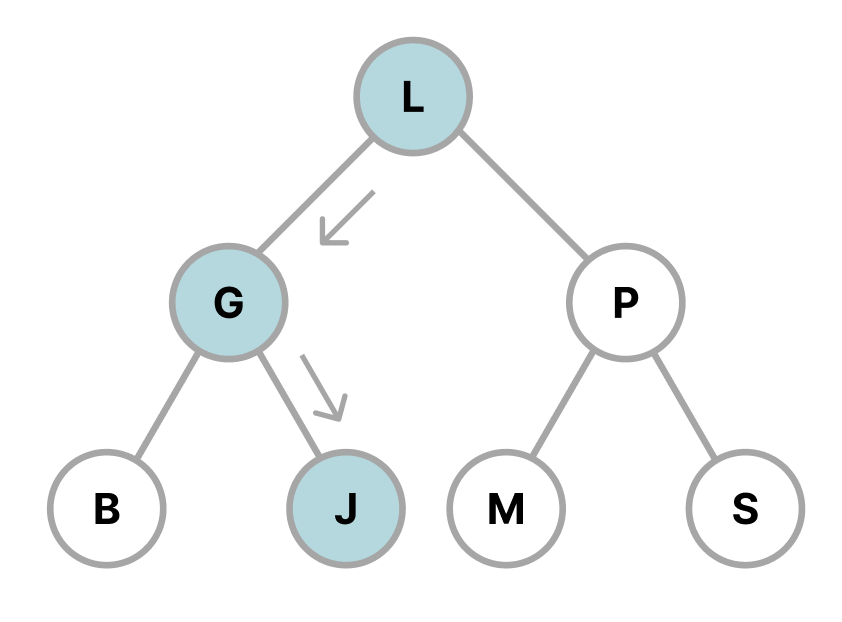
Figure 3: searching for letter J in the structure
The problem with such trees is that they can become too deep. This is where B-trees come in which are just a generalised form of BST and store more information in a single node. Although this makes operations slightly more difficult, the depth of the tree becomes a much bigger problem than asking questions for every node.
B-tree index in the database
There is no need to emphasise further how important fast data retrieval is. B-trees serve as the backbone mechanism and are the king of fast data retrieval in general scenarios. Here is an overview of how it works in the database:
- Key-value pairs: Each entry (node) in a B-tree index is a key-value pair. The key is the indexed column's value, and the value is a pointer to the corresponding record in the table (often a row's physical address on disk).
- Insertions: When a new row is added to a table, the B-tree index is updated. If a node overflows (exceeds the maximum number of keys allowed), it splits, ensuring the tree remains balanced.
- Removal: Removing a row implies updating the B-tree index. If a node underflows (falls below the minimum number of keys), it can borrow keys from neighbours or merge with them.
- Search and Retrieval: Due to the sorted nature of keys within B-tree nodes and the tree's balanced state, finding a specific key becomes exceptionally efficient. The database system starts at the root and traverses down the tree, choosing the appropriate child pointer at each node based on the desired key.
Benefits of B-tree indexing
The B-tree structure is designed for common use-cases such as range queries, ordered data retrieval (achieved automatically through the in-order algorithm), and efficient data removal. Although removing a row from the tree sometimes require rebalancing, the overall access speed is actually faster in bigger databases. Here is an overview of advantages, lets ignore drawbacks for now:
Efficient Range Queries: Given that the data within B-tree nodes is inherently sorted, it's adept at handling range queries. For example, finding all entries between two values is far more efficient with a B-tree compared to full-table scan.
Dynamic Nature: B-trees are dynamic, automatically restructuring themselves to maintain their balance, ensuring consistently optimal performance. If a tree becomes too deep and not balanced, we lose the advantages.
Consistency in Access Time: Again, due to the balanced nature of B-trees, they offer uniform access times, regardless of the key distribution or the specific key being accessed.
Optimized for Disk Storage: B-trees are particularly suited for disk-based storage systems. Their design minimizes disk I/O by ensuring that large chunks of data can be read or written in a single operation, which is far more efficient than multiple, smaller operations.
Scalability: B-trees scale well. As databases grow, B-trees effectively manage increasing volumes of data while still ensuring efficient access.
Drawbacks and limitations
Finally, like all data structures in CS, B-tree indexes come with their own set of challenges:
Maintenance Overhead: Every insertion, deletion, or modification in the indexed columns means the B-tree index needs updating. This overhead can be significant, especially in write-heavy systems.
Space Overhead: While B-trees optimize disk I/O, they do consume additional storage space. Especially in cases with numerous indexes, the combined size of indexes can sometimes exceed the size of the data being indexed!
Bulk Insert Performance: In scenarios where large volumes of data need to be inserted quickly, the continual maintenance of B-tree indexes can slow down the insertion process. Some databases address this by temporarily disabling indexes during bulk inserts.
Not Always the Best Fit: For some specific types of queries or data patterns, other indexing techniques or data structures (like hash indexes, bitmap indexes, or R-trees) might be more efficient.
Let’s check the size of our index in the database:
-- showing the index size - 199MB
SELECT
indexname AS index_name,
pg_size_pretty(pg_relation_size(quote_ident(indexname)::text)) AS index_size
FROM pg_indexes WHERE tablename = 'users';Best practices
B-tree indexing, while powerful, isn't a one-size-fits-all solution. Here are some things to keep in mind when deciding to implement B-tree indexes:
Choose columns wisely: Not every column in a database table needs an index. Prioritize columns that are frequently searched upon or are part of WHERE clauses in SQL statements.
Monitor Index Size: Regularly check the size of your indexes. As previously mentioned, indexes can sometimes grow larger than the actual data, leading to unnecessary space consumption.
Avoid Over-Indexing: Each additional index increases the write overhead, as more structures need updating with each data modification. It's a balancing act between read optimization and write performance.
Regular Maintenance: Over time, as data is added and removed, indexes can become fragmented. Periodic maintenance operations, such as rebuilding or reorganizing indexes, can help maintain optimal performance.
Conclusion
The importance of efficient and fast data retrieval cannot be overstated. B-tree indexes have stood the test of time, proving to be a robust and adaptable solution to the challenges posed by ever-growing datasets. While they have limitations, their strengths in managing large-scale data, optimizing disk I/O, and ensuring balanced and consistent performance make them an essential tool in modern database systems. As we generate and rely on more data, structures like B-trees will continue to be at the forefront, ensuring quick access to the data we need.