Database indexing internals - multi-column B-tree
by Davor Lozic, CTO
Database indexing series:
-
Database indexing - B-tree part 2 - multi-column indexes
Introduction
B-trees, as discussed in our previous article, are a type of self-balancing tree structure that maintains sorted data. They enable efficient insertion, deletion, and search operations, making them valuable in database management. B-tree indexes play a crucial role in the quick retrieval of data. While our previous article focused on single-column B-trees, there is another dimension to explore: multi-column B-tree indexes. This article will get into the complexities of these multi-column wonders and demonstrate their effectiveness in solving complex query scenarios.
Before we start, let’s quickly introduce list of technologies used in the example again:
- Python 3 with Faker to generate the data
- Postgres 16 database management system
- Low-resource server on Amazon (few GB of swap memory)
Example
We’ve generated 30M records in Postgres for a simple users table with Python and Faker:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL
);
Let's test the speed of a simple query and ask the database engine to explain its execution plan to us:
-- counting without index
SELECT COUNT(*) FROM users WHERE first_name = 'Tina'; -- 10s
SELECT COUNT(*) FROM users WHERE last_name = 'Harper'; -- 10s
-- 11s
SELECT COUNT(*) FROM users WHERE first_name = 'Tina' AND last_name = 'Harper';
-- postgres says it's gonna perform a full-table scan
-- newer versions (> 9.6) will say parallel full-table scan
EXPLAIN SELECT COUNT(*) FROM users WHERE first_name = 'Tina' AND last_name = 'Harper';Now, we will add a multi-column B-tree index on both last_name and first_name in users relation.
-- creating index on (last_name, first_name) combination - 2m 6s
CREATE INDEX idx_users_name ON users USING btree(last_name, first_name);
-- Q1 - 340ms
SELECT COUNT(*) FROM users WHERE first_name = 'Tina'
AND last_name = 'Harper';
-- Q2 - 330ms
SELECT COUNT(*) FROM users WHERE last_name = 'Harper';
-- Q3 - important(!) case which doesn't work (doesn't use the index)
-- 9s
SELECT COUNT(*) FROM users WHERE first_name LIKE 'Tina';If you have read our previous article about indexes, you already understand that adding an index on a column creates a B-tree which allows for faster traversal, compared to a full table scan. However, you may wonder why Q1 and Q2 utilize the index while Q3 does not (still takes 9 seconds!). The key factor lies in the order of the columns during index creation. Let’s first go over some basics.
Basics of multi-column B-tree indexes
Multi-column indexes, also known as composite indexes, are indexes that cover multiple columns of a table. They allow for the establishment of a hierarchy of keys, where the index first sorts by the first column and then by the second column (within the context of the first), and so on.
The main difference between a single-column and a multi-column index lies in their key structure. A single-column index maps individual column values to their respective locations in the database. On the other hand, a multi-column index combines several columns into one key, creating a hierarchy and making it effective for queries involving multiple column conditions. If the index is on columns A and B, each key will be a pair of values (value from A, value from B). This composite key determines the position in the B-tree, ensuring an ordered structure. In a multi-column B-tree index, the data is sorted based on the order of the columns specified during index creation. If the first column contains duplicate values, the subsequent columns in the index specification determine the sort order for those specific records, and so on - multi-column index can have many columns.
That’s all fine but why is column order so important?
Imagine having a large Excel spreadsheet where the first column contains last names and the second column contains first names. Also imagine that the data is sorted first by last name and then, within that context, by first name (see Figure 1).
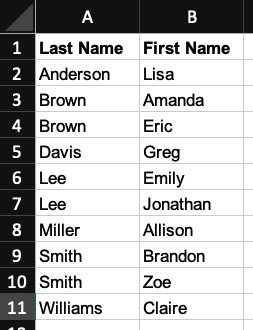
Figure 1: names sorted by last name and then by first name
If you search for a person by their last name and then by their first name, you can quickly find what you're looking for. However, searching by first name alone won't be helpful because the dataset isn't sorted by first name, and you would still need to search the entire Excel file.
Database engines are intelligent enough to utilize the index if you search by either the combination of (last name, first name) or just the last name. Even if we consider a third column, we would only perform a "full-table search" on the subset of data, which no longer qualifies as a full-table search. It's easy for an engine to filter out 99% of the data based on the last name and then perform a row-by-row search on that specific subset.
More complex example
Let’s try another example with millions of rows:
CREATE TABLE books (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
author VARCHAR(255) NOT NULL,
genre VARCHAR(100),
publish_date DATE NOT NULL,
isbn VARCHAR(13) UNIQUE,
pages INT,
book_language VARCHAR(50)
);
-- creating the index
CREATE INDEX idx_books ON books (author, genre, publish_date);Now, let’s again analyze which queries would use the index:
-- Queries that fully utilize the index
-- Q1
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy';
-- Q2
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy' AND genre = 'Fiction';
-- Q3
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy' AND
genre = 'Fiction' AND
publish_date = '1877-01-01';All three Q1, Q2, and Q3 fully utilize the index. The engine does not need to analyze rows individually because all rows are accessible directly through the index. However, there are situations where the engine is forced to perform a full-table search. Let's look at some examples:
-- Queries that ignore the index
-- Q4
SELECT COUNT(*) FROM books WHERE genre = 'Fiction';
-- Q5
SELECT COUNT(*) FROM books WHERE publish_date = '1877-01-01';
-- Q6
SELECT COUNT(*) FROM books WHERE genre = 'Fiction' AND
publish_date = '1877-01-01';As you can see, any query (Q4, Q5, and Q6) that doesn’t contain the author in the WHERE clause will ignore the index because we’ve build the index with combination of (author, genre, publish_date). Let’s see examples where the engine would use the index partially (making a row-by-row analysis after filtering the subset):
-- Queries that partially utilize the index
-- Q7
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy' AND
publish_date = '1877-01-01';
-- Q8
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy' AND
book_language = 'German';
-- Q9
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy' AND
genre = 'Fiction' AND
book_language = 'German';
-- Q10
SELECT COUNT(*) FROM books WHERE author = 'Tolstoy' AND
genre = 'Fiction' AND
publish_date = '1877-01-01' AND
book_language = 'German';Just to ensure that you understand all examples of partially using the index: publish_date.
- Q8 uses the index to find all Tolstoy books and then the engine performs a row-by-row search within that subset for a book_language.
- Q9 uses the index to find all fictional Tolstoy books, and then the engine performs a row-by-row search within that subset for a German book_language.
- Q10 uses the index to find all fictional Tolstoy books written in 1877, and then the engine performs a row-by-row search within that subset for a German book_language.
I get it now! But how to choose the column order?
Now that’s a million dollar question! It depends on the query you want to speed up. Take several SELECT examples on the same table, analyze which columns are common and which are most frequently used as filters or sorting criteria. The columns that are frequently used in WHERE clauses or ORDER BY statements should typically be prioritized in the index column order. Additionally, consider the cardinality of the columns – columns with higher cardinality (more unique values) can often be more beneficial when placed earlier in the index. In our example, author has a higher cardinality than genre. Remember, the objective is to narrow down the result set as quickly as possible using the index so the engine doesn’t have much to do when it needs to filter out the subset. Smaller the resulting subset, faster the query will be.
Limitations of multi-column indexes
Partial Use of Index
If a query only references the latter columns in the index without including the earlier ones, the database might not use the multi-column index, potentially leading to a full table scan.
Increased Storage Requirements
Although they can sometimes reduce the number of single-column indexes needed, multi-column indexes still demand additional storage space, especially when they include numerous columns. Our one-column index from last article was around 190MB while this one is 220MB.
Dependency on Database Engine
Different database engines have distinct ways of handling indexes. It's crucial to understand the specific behaviors and quirks of the chosen database system to get the maximum benefit from multi-column indexing.
Trade-offs between write and read speeds
While read operations (SELECT queries) can benefit immensely from multi-column indexes, write operations (INSERT, UPDATE, DELETE) can be slower due to the additional time needed to update the index.
Conclusion
Mastering the internals of database indexing is essential for optimizing query performance. Multi-column indexing in particular can speed up queries involving multiple attributes. As we've seen in the example on the users and books table, the order of columns in the index, the nature of the queries, and the data distribution all impact the index's efficiency. While it may be tempting to over-index tables for improved performance, it's important to consider the storage and maintenance costs of indexes. Striking the right balance based on your specific use-case and querying patterns is crucial. Remember to periodically review and refine indexes, and monitor them closely to maintain a responsive and efficient database system.